隨著 2026 年生成式 AI 與邊緣運算技術的成熟,全球微控制器(MCU)市場正經歷一場前所未有的技術革命。過去,MCU 主要扮演訊號採集與簡單邏輯控制的角色;而今,隨著 Arm Cortex-M55 核心的普及以及Cortex-M85 核心的市場化,加上專用 NPU(神經處理單元) 的硬體化(將 NPU 的電路圖(IP 核心)直接整合進了晶片的內部佈局),邊緣設備已具備在毫瓦級功耗下執行複雜影像辨識、語音處理、甚至是小型語言模型(SLM)的能力。
本文中將剖析 ST、Renesas、NXP、TI、新唐(Nuvoton)、高通、聯發科及新銳廠商 Alif Semiconductor 針對Edge AI的最新MCU方案,為開發者提供一些選擇參考。
MCU 廠商 AI 核心架構現況
目前的 Edge AI MCU 市場已形成「通用效能型」與「專用加速型」兩大流派。以 STMicroelectronics (意法半導體) 為例,該公司在 2026 年正式量產的 STM32N6 系列中,捨棄了外掛加速器的思維,轉而整合自研的 Neural-ART 加速器。該 NPU 在 1 GHz 時脈下可提供高達 600 GOPS 的算力,並與支援 Helium 技術的 Cortex-M55 核心深度整合。這種設計讓開發者能在不犧牲即時性的前提下,處理高畫質的影像辨識任務,如工廠自動化中的瑕疵檢測。
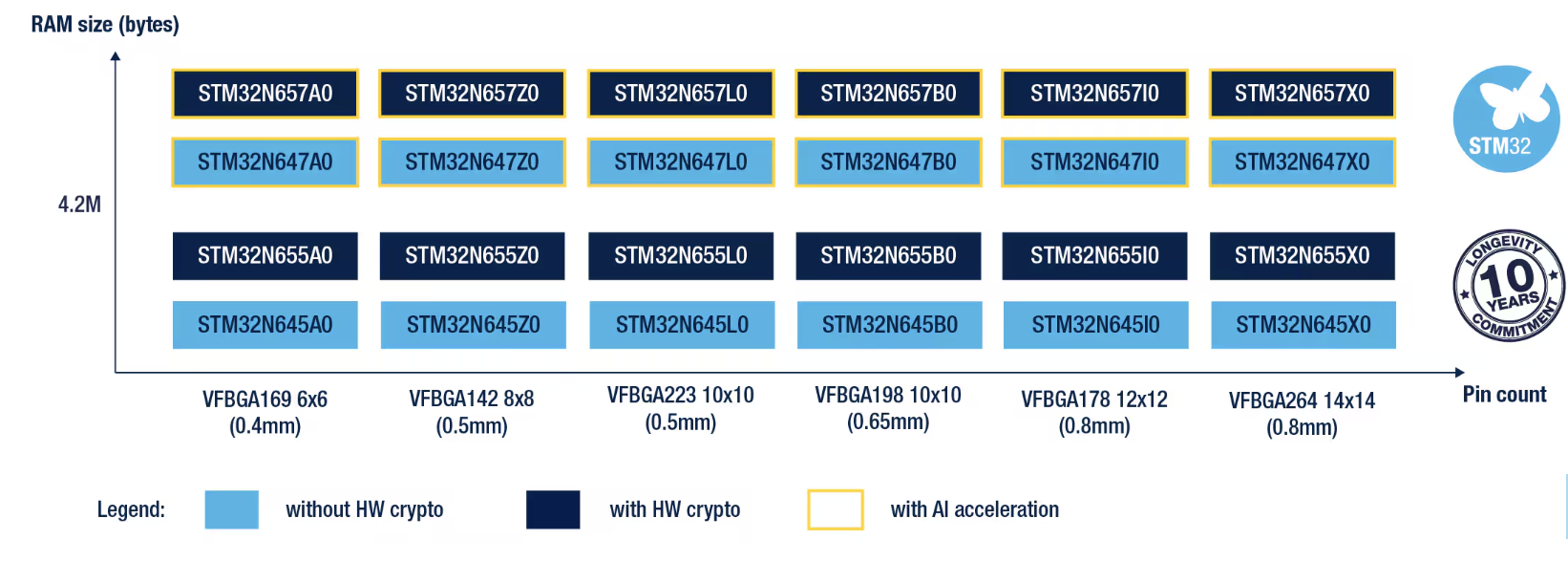
STM32N6產品系列(source)
與此相對,Renesas (瑞薩電子) 的 RA8P1 則是全球首款將 Cortex-M85 核心與 Arm Ethos-U55 NPU 結合的量產產品。Cortex-M85 本身具備的 Helium 向量擴展技術,能提供優於傳統 M7 核心 4 倍的 DSP 效能,再加上專用 NPU 的助陣,其總體 AI 推理速度提升了近 35 倍。這使得 RA8 系列在預測性維護與複雜音訊處理中佔據技術高點。

RA8P1功能表(source)
下表彙整 2026 年4家MCU廠商旗艦級 AI MCU 之運算核心與理論算力指標,供高階效能評估參考。
| 廠商系列 | 主要核心 (CPU) | AI 加速核心 (NPU) | 理論算力 (GOPS) | 製程技術 |
|---|---|---|---|---|
| ST STM32N6 | Cortex-M55 (800MHz) | Neural-ART | 600 GOPS | 40nm / 28nm |
| Renesas RA8P1 | Cortex-M85 (1GHz) | Ethos-U55 | 256 GOPS (@500MHz) | 22nm ULL |
| NXP i.MX RT700 | Cortex-M33 (Dual) | eIQ Neutron N3-64 | N/A (低時延優化) | 28nm FD-SOI |
| Nuvoton M55M1 | Cortex-M55 (220MHz) | Ethos-U55 | ~128 GOPS | 40nm |
差異化競爭:工控即時性與超低功耗之爭
德州儀器 (TI) 的方案在 2026 年展現了鮮明的工控色彩。C2000 TMS320F28P55x 系列打破了傳統 AI 僅限於資料處理的範疇,將 AI 直接引入即時電力控制循環中。TI 的工程設計確保了 NPU 在執行推理(如預測逆變器故障)時,不會佔用主 C28x DSP 的頻寬,這對於需要微秒級反應的馬達驅動與數位電源至關重要。其 AI 故障偵測準確度高達 99%,顯著降低了工業設備的非計畫性停機時間。

在超低功耗領域,Ambiq 憑藉其專利的 SPOT® (次臨界功耗優化技術) 成為穿戴式設備的首選。其 Apollo510 雖然沒有專用 NPU,但透過高效能的 Cortex-M55 Helium 技術與自研的電源管理,將 AI 任務的每焦耳效能提升了 300 倍。這類方案定位於「始終在線 (Always-on)」的健康監測,確保在電池供電環境下仍能進行複雜的生物訊號分析。
高通與聯發科:通訊大廠的邊緣 AI 降維打擊
高通 (Qualcomm) 與聯發科 (MediaTek) 的切入點則更偏向「系統級 AIoT」。高通於 2026 年發表的 Dragonwing Q-series 徹底模糊了 MCU 與 MPU 的界線。旗艦型號 Q-8750 具備驚人的 77 TOPS 算力,這主要歸功於其 Hexagon NPU。此類產品定位於高階邊緣伺服器與具備生成式 AI 功能的智慧相機,甚至能直接運行 110 億參數的 LLM。此外,高通整合了 Arduino 的生態體系,大幅降低了傳統嵌入式工程師進入高效能 AI 領域的門檻。

聯發科則以 Genio 系列主打多媒體與連網 AI 的結合。其產品優勢在於將 5G/Wi-Fi 7 通訊模組與 AI 運算單元整合。對於需要高度整合、具備語音助理功能的智慧家電開發商而言,聯發科提供的一站式解決方案在成本與開發週期上具有極大優勢。

新銳挑戰者:Alif 的融合架構
Alif Semiconductor 作為後起之秀,在 2026 年以 Ensemble™ 系列展示了「多核心異構」的極致。其產品現況如下:
-
三位一體架構: 單晶片內含負責 OS 的 Cortex-A32、負責即時控制的 Cortex-M55、以及負責 AI 的 Ethos-U85 NPU。
-
Transformer 硬體支援: 它是目前市場上極少數在單晶片微控制器等級,就提供支援 Transformer 網絡(即生成式 AI 基礎架構)硬體加速的廠商,算力高達 450 GOPS。
-
MRAM 技術應用: 內建高達 5.5MB 的 MRAM (磁性隨機存取記憶體),解決了傳統 Flash 讀取 AI 權重模型速度緩慢與壽命受限的問題。

下表針對不同垂直產業需求,評估各家廠商的技術優勢與專屬功能。
| 廠商名稱 | 應用定位 | 獨家技術亮點 | 核心算力優勢 |
|---|---|---|---|
| 德州儀器 (TI) | 電力電子與即時控制 | NPU 與 C28x DSP 硬體隔離 | 99% 故障偵測準確率 |
| Alif Semi. | 生成式 AI / 穿戴式 | Ethos-U85 (支援 Transformer) | 450 GOPS / 高能效比 |
| 高通 (Qualcomm) | 高階 AIoT / 視覺中心 | Hexagon NPU 整合 | 高達 77 TOPS (INT8) |
| Ambiq | 極低功耗感測 | SPOT® 亞閾值功耗技術 | 推理吞吐量提升 300 倍 |
軟體生態系與開發平台之關鍵角色
算力固然重要,但開發工具的便利性決定了產品落地的速度。目前各廠商均推出了專屬的 AI 工具鏈:
-
STMicroelectronics (STM32Cube.AI): 支援將主流框架(Keras, TensorFlow Lite)轉換為高度優化的 C 程式碼。
-
Renesas (AI Navigator): AI Navigator 整合了邊緣 AI 開發所需的功能,可用於縮短開發時間。
-
NXP (eIQ ML Software): 強調安全開發流程,支援與 EdgeLock 安全單元整合。
-
新唐 (NuEdgeWise): 專為微型 AI 模型訓練與量化設計,適合本土開發者快速上手。
下表針對軟體工程師評估開發門檻,整理各家工具特色與模型相容性。
| 廠商 | 主要開發工具 | 模型相容性 | 特色功能 |
|---|---|---|---|
| ST | STM32Cube.AI | Keras, TFLite, ONNX | 雲端算力估算工具 |
| Renesas | Reality AI / Workbench | TensorFlow, PyTorch | 自動化異常檢測演算法 |
| NXP | eIQ® ML Software | GLOW, TFLite Micro | 硬體加密與 AI 模型保護 |
| Qualcomm | AI Hub / SNPE | PyTorch, Caffe2 | 大型模型量化技術 |
M55、M85 與 Ethos-U55 的戰略定位
在深入探討邊緣 AI 的硬體實現時,理解 Arm Cortex-M55、M85 處理器與 Ethos-U55 NPU 之間的定位差異至關重要。Cortex-M55 的推出標誌著嵌入式處理器正式進入「向量運算時代」,其內建的 Helium 技術讓 MCU 無需外掛加速器即可處理基礎的數位訊號與輕量級機器學習任務,適合對於成本與功耗極度敏感的「始終在線」感測應用。
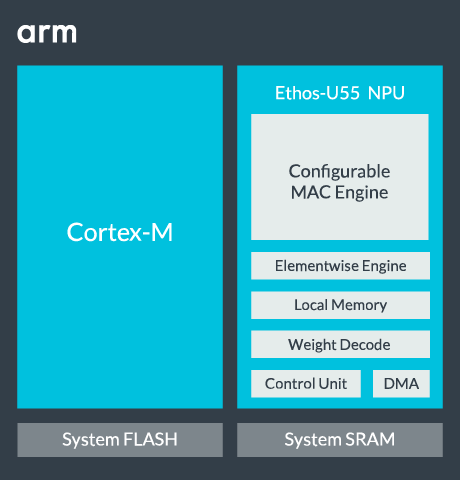
作為目前效能頂峰的 Cortex-M85,則是在 M55 的基礎上進一步強化了純標量運算與系統安全性,其主頻大幅提升且具備更優異的架構效率,定位於取代入門級應用處理器,負責處理複雜的系統邏輯、高階加密及中等規模的 AI 推理。
然而,當應用場景涉及實時高解析度影像辨識或多語種語音處理時,單靠處理器核心的向量擴展已不足以應付龐大的矩陣運算需求,這正是專用 NPU——Ethos-U55 存在的價值。Ethos-U55 並非獨立運行的處理器,而是作為一個高效能的「運算外包中心」,專職處理神經網路中密度最高、最耗電的卷積運算。
在典型的異構架構中,Cortex-M55 或 M85 擔任「大腦」角色,負責周邊管理與決策邏輯,而將繁重的卷積負載卸載至 Ethos-U55。這種「大腦控制、核心加速」的協作模式,讓邊緣設備能在維持毫瓦級低功耗的同時,獲得相較於傳統架構數百倍的 AI 效能提升,實現了真正的運算效率最大化。
下表對比運算核心(CPU)與加速核心(NPU)之功能差異,協助開發者依模型複雜度進行選型。
| 核心名稱 | 硬體定位 | AI 運算技術 | 最佳應用場景 | 效能亮點 |
|---|---|---|---|---|
| Cortex-M55 | 通用處理器 (CPU) | Helium (向量擴展) | 基礎語音辨識、震動分析 | 平衡功耗與基礎 AI 能力 |
| Cortex-M85 | 高效能處理器 (CPU) | 優化版 Helium / 高主頻 | 工業自動化、高階 HMI | 最強單核控制與標量效能 |
| Ethos-U55 | 專用 NPU (加速器) | 硬體化矩陣運算單元 | 人臉辨識、多語言關鍵字 | 推理速度較 CPU 提升數十倍 |
| M55/M85 + U55 | 異構 AI 系統 | CPU 決策 + NPU 推理 | 複雜視覺與實時邊緣決策 | 兼具極低功耗與極高算力 |
結語
2026 年的 Edge AI MCU 市場已不再是單純的算力競賽,而是 「架構精準化」 的競爭。對於工業用戶而言,TI 的控制優先與 ST 的視覺優化架構是首選;對於消費電子,瑞薩與新唐提供的平衡性方案更具性價比;而對於追求頂尖效能、欲在終端實現生成式 AI 應用的開發者,Alif Semiconductor 與高通則是當前技術天花板的代表。選擇邊緣 AI 方案時,除了 TOPS/GOPS 等純算力指標,功耗效率 (TOPS/W) 與工具鏈的整合完整度,才是決定產品能否成功上市的關鍵指標。
(作者:歐敏銓)
》延伸閱讀:
-
STMicroelectronics: STM32N6 High-Performance MCU Specs – ST Neural-ART 技術詳解
-
Renesas Electronics: RA8P1 Arm Cortex-M85 & Ethos-U55 NPU Documentation – Cortex-M85 效能基準測試
-
Texas Instruments: TMS320F28P55x C2000 Real-Time AI MCU Datasheet – 工業邊緣 AI 實時控制白皮書
-
Alif Semiconductor: Ensemble Series E8 GenAI Capabilities – Ethos-U85 與 Transformer 加速技術資料
-
Qualcomm: CES 2026: Dragonwing Q-Series Launch Press Release – 77 TOPS 邊緣 AI 處理器架構說明

- 【產業剖析】全球機器人生態系競合趨勢 - 2026/06/22
- 【產業剖析】人形機器人火熱背後的現實難題 - 2026/06/15
- 【COMPUTEX 2026】以「具身智慧界Android」為定位的韓國Circulus - 2026/06/05
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


