


YOLOv12的改變:向Transformer、Attention靠攏!
最新版本 的YOLOv12延續了 YOLO 系列一貫的「高速 + 準確」的設計理念,但在架構、訓練方法與推論效率方面均有顯著改進,並且更加靠近 transformer 技術與多模態學習的整合,本文將做個介紹。

讓低功耗行動AI落地!OpenMV推 AI 相機模組
創客熟悉的OpenMV也推出內嵌NPU、支援行動AI運算的相機模組了,其核心分別來自ST及ALIF,並上架Kickstarter達標了。這兩款模組的技術特色為何,且看本文介紹。
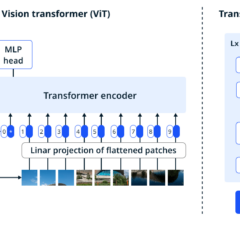
AI物件辨識技術比一比:ViT vs YOLO
ViT(Vision Transformer)與 YOLO(You Only Look Once)都是知名的物件辨識技術,但它們在架構、應用場景和優勢方面有明顯的不同,本文將針對兩大技術來做一個比較。


【 Edge AI專欄】使用Intel OpenVINO搭配YOLOv11輕鬆駕馭姿態偵測
Intel OpenVINO 在開源範例庫 Notebooks 上給出 YOLOv11 物件偵測、姿態估測及影像分割等三個案例。本篇文章,會跟著源碼說明來了解一下如何運行 【姿態估測】 範例「Convert and Optimize YOLOv11 keypoint detection model with OpenVINO™」及動作原理。
如何客製化企業 RAG 知識庫?— 從資料庫到知識整合的實戰技術
