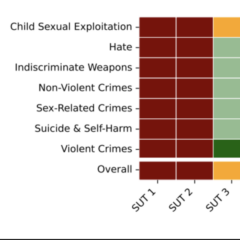
LLM/GenAI的回答會造成危害嗎?MLCommons提出衡量規範草案
針對LLM/GenAI會否造成危害?該如何衡量危害程度?對此MLCommons在今年4月提出LLM的安全性測試標準,稱為MLCommons AI Safety,目前僅為0.5版,其中是如何規範的呢?

TinyML效能基準測試:MLPerf Inference:Tiny 0.7版觀察
先前MLCommons公佈過一次0.5版的測試,約在去年六月,今年四月則再次更新,稱為0.7版,雖然一樣是非正式版,但參與測試的軟硬體陣容已大幅擴充,值得觀察!

【Benchmark】要如何衡量TinyML專案的執行效能?
近期TinyML蔚為時尚,為了能更公允評判TinyML軟硬體的特性表現,因而需要基準(Benchmark)測試,本文將介紹由MLCommons及EEMBC提出的兩套作法。