
作者: Jack OmniXRI
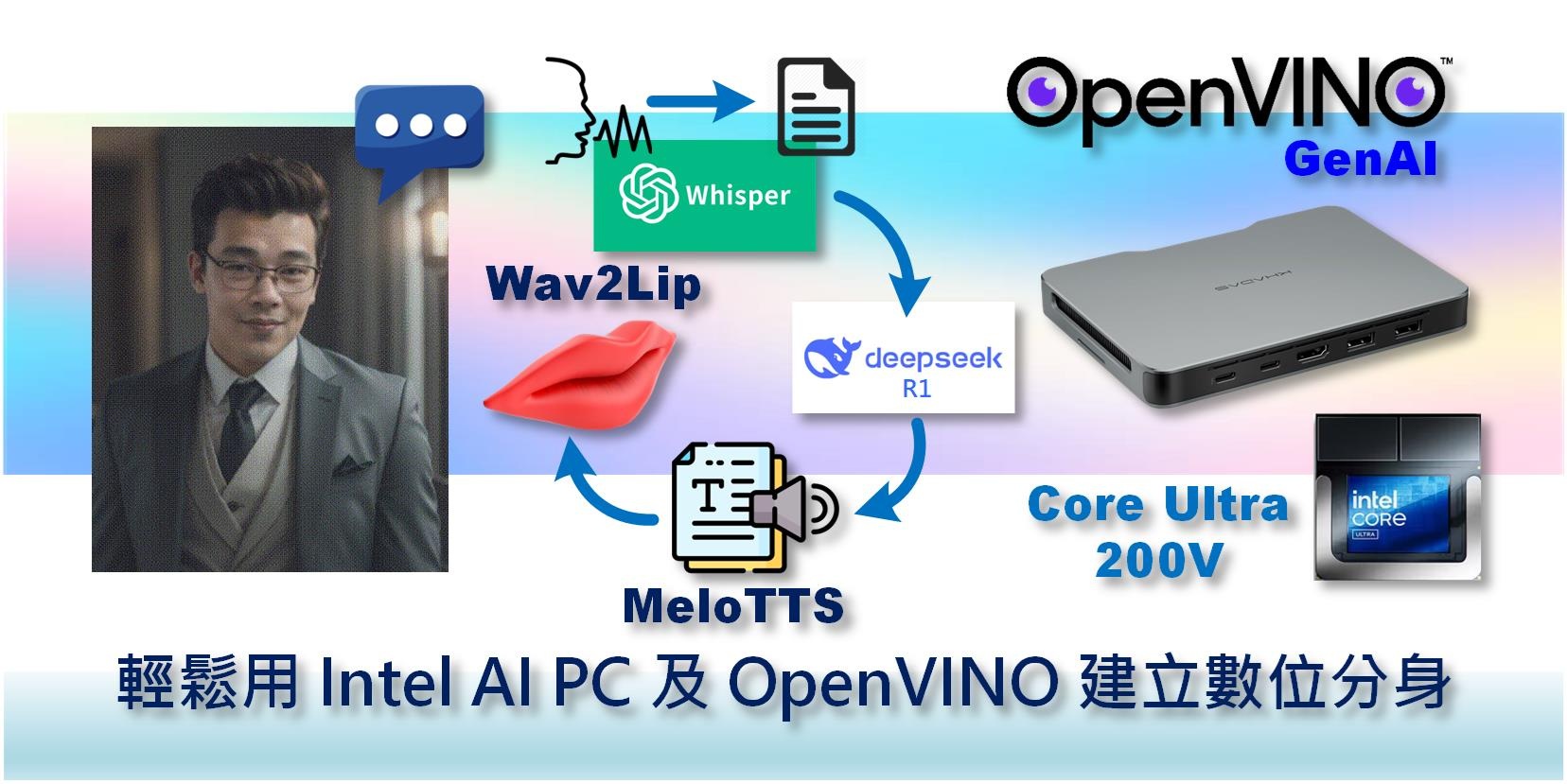
隨著生成式人工智慧(Generative Artificial Intelligence, GenAI)技術的日益普及,數位分身(Digital Avatar)或稱數字人(Digital Human)也開始出現在很多智慧客服及人機互動應用上,讓使用者再也不用面對冷冰冰的機器進行操作。一個完整的數位分身,就像真人一樣,要具有自然語言對話、豐富肢體動作和產生生動表情的能力,其中就需要用到許多生成式AI技術,包括利用語音轉文字(Speech to Text,STT)得到問題的文字,交給大語言模型(Large Language Model,LLM)進行文字問答,再將文字轉語音(Text to Speech,TTS)把答案讀出,最後再配合語音自動對嘴形(Lip Sync)讓人物影像的嘴巴也能和語音同步動起來。
去(2024)年底曾寫過一篇文章「如何使用 Intel AI PC 及 OpenVINO 實現虛擬主播」,介紹了數位分身所需擁有的文字轉語音和聲音自動嘴型功能,算是實現了數位分身的後半段「自動讀稿機」的能力。此次就來幫大家介紹前半段,使用麥克風收音進行問話,然後再使用大語言模型來思考及產生問答結果,如此就能搞定數位分身的前半段,構成一個簡單完整的系統。
在上一篇文章中使用的是 Intel 第一代 AI PC (Core Ultra 5 125H),這次將使用第二代 AI PC (Core Ultra 7 258V) 來進行測試。主要會使用到語音轉文字模型 Whisper 及大語言模型 DeepSeek-R1,運行時完全不用上網,所以不會有資安問題,但生成的內容是否滿足需求就暫不討論,這裡僅就生成反應速度進行討論。
以往我們都是使用 OpenVINO 標準版來進行開發,但其實在 2024.x 版之後就有提供 OpenVINO GenAI 版本可直接下載。這個版本算是基於標準版 Runtime API 加上生成式AI API,並可整合 Optimum-cli 及 Hugging Face ,可大幅簡化模型下載、推理及部署複雜度,還可針對 CPU / GPU / NPU 的硬體加速提供更好的推理性能,所以此次範例程式會採用 GenAI API 形式執行。
只需不到短短一分鐘...
輸入您的信箱與ID註冊即可享有一切福利!
會員福利
免費電子報
會員搶先看
主題訂閱
好文收藏

