
DeepSeek真開放?假開放?MOF提供測度參考
Linux基金會轄下的LF AI & Data基金會在去(2024)年3月發佈AI模型開放框架(Model Openness Foundation, MOF),明確表達了AI模型的開放包含17個關鍵部件(critical components)。

【創業小聚】「寫完程式,然後呢?」Zeabur用一鍵部署,解決AI時代開發者的最後一哩路!
Zeabur創辦人兼執行長林沅霖(首圖右)為此開發了「一鍵式部署服務」,讓不熟悉完整開發流程的新時代開發者也能輕鬆自動部署程式,同時提升專業開發者的效率,至今每月服務超過1.6萬名活躍用戶。
本機端AI統合安裝神器Pinokio
Pinokio類似一個Local AI App Store,下載安裝後可以直接瀏覽多種Local AI應用程式,看上哪一套後一鍵按下去,後續就自動完成所有的安裝,相依的軟體若本機端內本來缺乏的,也會在此一連續程序中自動順勢安裝完成。

【創業小聚】每秒回答千字、企業可自行部署,Mistral AI的AI助理Le Chat如何挑戰ChatGPT、DeepSeek?
法國AI新創Mistral AI於美國時間2月6日發布了AI助手Le Chat的多項更新,號稱可以每秒约1,000字的速度進行回答,提供比OpenAI、Anthropic的Claude、Google Gemini等模型更快速的體驗!

2025年CES展AI類創新獎觀察
每年一月的消費性電子展(CES)都會有創新獎的頒佈,雖然獎的頒佈有些浮濫,似乎在於增添展會氣勢,但有時有些獎確實具創意,值得參考,本文就人工智慧(AI)類的獲獎品進行進一步觀察。
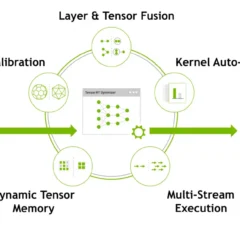
NVIDIA讓TensorRT-LLM推論效率增速三倍
最近(2024年12月)NVIDIA新發佈,在TensorRT-LLM中加入了推測性解碼技術,從而讓TensorRT-LLM的推論效率提升三倍。