作者:歐敏銓
2026 年的 VLA 技術現況顯示出明顯的兩極發展:開源模型專注於通用性與民主化,讓任何實驗室都能擁有基礎具身能力;閉環生態則專注於高頻控制與軟硬一體,挑戰大規模商業量產。
過去我們教機器人如何『移動』,隨著視覺-語言-動作(Vision-Language-Action, VLA)模型的爆發,現在我們教它們如何『思考物理世界』。進入2026 年,機器人可望告別僵硬的腳本時代,邁入具身智能(Embodied AI)的黃金盛世。本文將帶大家一起看看,有哪些值得關注的開源及閉源VLA模型。
一、 開源之火:打破「數據門檻」的社群化運動
開源社群是 2026 年 VLA 技術快速普及的推動力。以往具身智能(或稱「實體AI」)受限於高質量動作數據的取得與分析,才能建立精準的動作指令,但今年的開源模型展現了強大的泛化與抗干擾能力,代表性模型有:
OpenVLA:開發者的「標準底座」
OpenVLA 是由史丹佛大學、加州大學柏克萊分校及 Google DeepMind 等頂尖團隊於 2024 年底聯合推出的開源具身智能標竿模型。它的誕生旨在打破過去機器人模型「一機一模型」的孤島狀態,推動通用機器人智能的民主化。
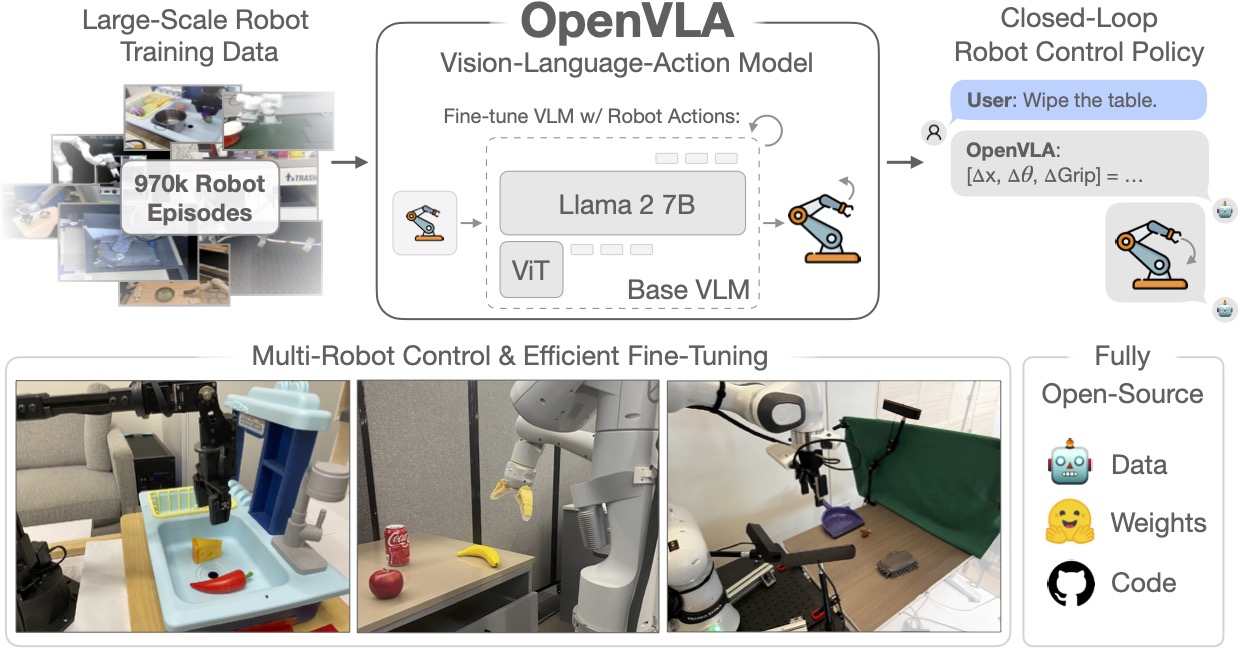
技術特色:
-
強大的模型骨幹: 基於 Llama-2 (7B) 建構,結合 DINOv2 與 SigLIP 雙視覺編碼器,使其具備深厚的常識推理能力與精細的視覺感知。
-
海量數據訓練: 在包含 71 個機器人數據集的 Open X-Embodiment 上完成預訓練,展現出卓越的跨硬體泛化性,能適應不同類型的機械臂。
-
動作編碼技術: 將連續的動作座標轉化為離散的「動作標記(Action Tokens)」,讓語言模型能像預測下一個字一樣預測機器人的下一個動作。
-
高效微調(PEFT): 支援低門檻的參數高效微調技術,讓研究人員僅需少量數據即可將模型部署於特定任務,大幅降低了開發成本。
OpenVLA 的開源性質使其成為目前具身智能研究中最受歡迎的「底座」,引領著機器人從單一技能走向通用智能。
Spirit v1.5:實戰派的巔峰
Spirit v1.5 是由中國具身智能新銳「千尋智能」(Seeking AI)於 2026 年初推出的重量級開源 VLA 模型。在具身智能評測標竿 RoboChallenge 中,它憑藉卓越的實戰表現超越了多項國際主流模型,成為目前全球開源界性能最強大的代表之一。

Spirit v1.5在RoboChallenge Table30 benchmark排名第一(2026/1/11)(source)
技術特色:
-
極強的環境魯棒性: 不同於傳統模型依賴高度清理後的演示數據,Spirit v1.5 在訓練中納入了大量的「非完美數據」(如遮擋、碰撞、滑落)。這使其在面對雜亂、動態變化的真實場景時,具備極強的自我糾錯與重新規劃能力。
-
統一 VLA 架構: 採用端到端的 Transformer 架構,將視覺感知、自然語言指令與動作輸出深度融合。其對物理空間的理解極為細膩,能實現釐米級的精準抓取。
-
高效的動作頻率: 該模型優化了推理延遲,支援高頻率的動作輸出,確保機器人在執行複雜連續任務(如摺疊柔軟衣物、拆卸精細零件)時動作流暢且不間斷。
-
數據驅動的泛化力: 透過大規模的異構數據訓練,Spirit v1.5 展現了出色的「零樣本學習」能力,即便面對未曾見過的物體或環境,也能根據指令推斷出正確的操作邏輯。
Spirit v1.5 的開源不僅提升了產業的基準線,更為中小型企業開發高性能機器人應用提供了極具競爭力的技術底座。
Octo:多模態靈活性的代表

Octo 是由加州大學柏克萊分校(UC Berkeley)領銜的八家頂尖學府與研究機構,於 2023 年底至 2024 年間推出的通用機器人策略模型。其命名寓意如章魚般靈活的多觸手控制,是具身智能領域從「專用模型」轉向「通用基礎模型」的重要里程碑。
技術特色:
-
基於擴散策略(Diffusion Policy): 不同於 OpenVLA 的自回歸架構,Octo 採用 Diffusion Transformer。這使其能學習「多峰值」的動作分佈,有效解決機器人在面對同一任務有多種達成方式時的決策模糊問題,生成的動作更加平滑自然。
-
多模態指令引導: Octo 具備極高的靈活性,支持多種輸入組合。用戶可以透過語言指令(如「拿取方塊」)、目標圖像(展示任務完成後的樣子)甚至是特定軌跡來引導機器人,適應多樣化的作業需求。
-
靈活的模塊化設計: 採用了區塊式的輸入編碼(Patching),使其能根據硬體配置輕鬆增減傳感器輸入(如增加腕部攝像頭或深度信息),且不需從頭訓練。
-
強大的跨平台能力: 在包含 25 種機器人平台、高達 80 萬個軌跡的數據集上訓練,Octo 展現了極佳的零樣本(Zero-shot)遷移能力,是開發者探索跨硬體協同的首選工具。
Octo 的開源為機器人社群提供了一個穩健且靈活的「策略骨幹」,特別在需要高度靈巧性與多種輸入引導的場景中表現卓越。
二、 閉環巨頭:算力與硬體一體化的極限競速
當開源模型在追求泛化時,科技巨頭們則利用垂直整合的優勢,將 VLA 推向量產與極致性能。代表性模型有:
NVIDIA GR00T N1:物理仿真的終極加速器
GR00T N1(Generalist Robot 00 Technology)是 NVIDIA 於 2024 年發布、並在 2025 至 2026 年迭代至成熟期的通用人形機器人基礎模型。它是 NVIDIA 執行長黃仁勳眼中 AI 的「下一個浪潮」,旨在為全球不同品牌的人形機器人提供統一的智能大腦。
技術特色:
-
大規模仿真訓練 (Sim-to-Real): GR00T 的核心優勢在於 NVIDIA 的 Isaac Lab。透過在虛擬環境中模擬數萬次物理交互,機器人能在極短時間內學會複雜動作,並利用強大的遷移算法解決現實世界中的物理誤差。
-
多模態輸入與全身協調: 該模型能同時處理語義指令、視覺影像及人類示範影像。特別擅長「全身控制」(Whole-body Control),讓機器人在行走、保持平衡的同時,還能流暢地執行雙手協同任務。
-
邊緣算力優化: 專為 Jetson Thor 機器人運算平台設計,採用全新的 GPU 架構來處理 VLA 模型的高負載推理,確保機器人具備毫秒級的反應速度。
-
模仿學習與泛化: 透過觀看人類操作影片,GR00T 能快速模仿人類的動作軌跡。其強大的泛化能力使其不限於單一品牌硬體,從 Figure 02 到 Unitree H1 均能適配。
GR00T 的出現標誌著機器人從「預設程式」轉向「自主學習」,是目前產業鏈整合度最高的具身智能方案。
Google Gemini Robotics:擁有「博學大腦」的管家
Gemini Robotics(前身為 RT 系列)是 Google DeepMind 在 2025 年底至 2026 年推出的旗艦級具身智能方案,旨在將 Gemini 的大規模多模態理解力從數位世界擴展至物理世界,讓機器人具備「先思後行」的能力。

Gemini Robotics模型淵源圖(圖片來源:陸向陽)
技術特色:
-
「雙腦協同」架構:Gemini Robotics-ER (大腦)負責高階具身推理(Embodied Reasoning)。它能將模糊的自然語言指令(如「清理桌上的污漬」)拆解為多步驟計畫,並進行空間與時間上的因果推理;Gemini Robotics 1.5 (小腦/VLA)則負責底層動作執行。它是一個純粹的 VLA 模型,直接將視覺與指令映射為馬達控制訊號,輸出頻率高且動作平滑。
-
思維鏈動作 (Thinking VLA): 這是其 2026 年最核心的突破。機器人在執行前會進行「內部模擬」,預測動作結果並在腦中修正,這使得它在處理 origami(摺紙)或玩牌等高靈巧任務時,成功率大幅提升。
-
跨實體運動遷移 (Motion Transfer): 具備極強的泛化性,無需針對特定硬體重新訓練。同一個模型能無縫控制 Boston Dynamics 的新一代 Atlas、Apptronik 的 Apollo 或是工業機械臂,實現「技能共享」。
-
代理化能力 (Agentic Capabilities): 模型能主動調用工具(如 Google 搜尋)獲取未知資訊,或在偵測到環境變化(如物體倒下)時即時調整策略。
Gemini Robotics 目前主要透過 SDK 提供給 Boston Dynamics、Agility Robotics 等頂尖合作夥伴,是邁向通用人工智能(AGI)物理載體的關鍵一步。
》延伸閱讀:Gemini Robotics 1.5版觀察
三、 Tesla Optimus Gen 3:硬體定義軟體的革命
Tesla 走的是一條孤獨但極其高效的道路:極簡主義的端到端網路。
-
FSD-v15 遷移: Optimus Gen 3 並未採用通用的 VLA 框架,而是直接運行改造後的自動駕駛網路。它直接輸出扭矩與電流指令,減少了中間層的損耗。
-
Grok-5 嵌入: 透過 xAI 的 Grok 大模型,Optimus 具備了原生語音交互與物理世界建模能力。
-
量產優勢: 2026 年 Optimus 已在 Tesla 德州工廠大規模部署,負責搬運 4680 電池單元,這種「實戰餵養」出的 VLA 模型,在工業穩定性上無人能敵。
》延伸閱讀:2026量產版人形機器人對決:波士頓動力Atlas vs. 特斯拉Optimus
結語
2026 年的 VLA 技術現況顯示出明顯的兩極發展:開源模型專注於通用性與民主化,讓任何實驗室都能擁有基礎具身能力;閉環生態則專注於高頻控制與軟硬一體,挑戰大規模商業量產。
當 VLA 模型學會了語言理解及物理常識,機器人便不再是冷冰冰的機器,而是能理解「重力」、「易碎」與「輔助」的智能實體。我們正站在一個奇點:機器人不再是為特定任務設計,而是為了「理解世界並參與人類世界」而生。
》延伸閱讀:
-
OpenVLA 官方專案主頁:了解如何微調您的第一個機器人基礎模型。
-
NVIDIA Project GR00T 技術白皮書:深入研究 Isaac Lab 如何縮小仿真與現實的差距。
-
DeepMind Robotics 研究日誌:探索 Gemini 如何賦予機器人高級推理能力。
-
Tesla AI & Robotics 官方頁面:追蹤 Optimus Gen 3 的最新量產進度與端到端架構。
-
RoboChallenge 2026 實時榜單:查看全球具身智能模型的最新實測排名。

- 【產業剖析】全球機器人生態系競合趨勢 - 2026/06/22
- 【產業剖析】人形機器人火熱背後的現實難題 - 2026/06/15
- 【COMPUTEX 2026】以「具身智慧界Android」為定位的韓國Circulus - 2026/06/05
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!


