
近來VLM當紅,也讓Transformer-based的ViT(Vision Transformer)受到極大的關注,但YOLO(You Only Look Once)這個即時物體偵測(real-time object detection)演算法的重要性仍不減,其技術上也仍在進步,於 2025 年 2 月 18 日 正式發布了最新版本 – YOLOv12。它延續了 YOLO 系列一貫的「高速 + 準確」的設計理念,但在架構、訓練方法與推論效率方面均有顯著改進,並且更加靠近 transformer 技術與多模態學習的整合,以下來做個介紹。
技術細節與新特點
YOLOv12 引入了以注意力機制(Attention)為核心的架構,突破了傳統基於卷積神經網路(CNN)的限制,實現了更高的準確性和更低的延遲,特別是在 Microsoft COCO 數據集上的表現顯著提升。注意力機制(Attention Mechanism)是一種模仿人類「聚焦注意力」行為的神經網路技術,能夠讓模型在處理輸入資料時動態地選擇重要資訊,忽略不相關或不重要的部分,有助於提升模型的感知力與語義理解力。
YOLOv12 的主要定位依然是「極致高效的目標檢測模型」,但透過模組化設計與部分 Transformer 成分的融合,它也正在逐漸向更「泛化的多模態世界」靠攏。此外,YOLOv12 還推出了 YOLOv12-turbo 版本,進一步加快了推理速度,滿足即時應用的需求。
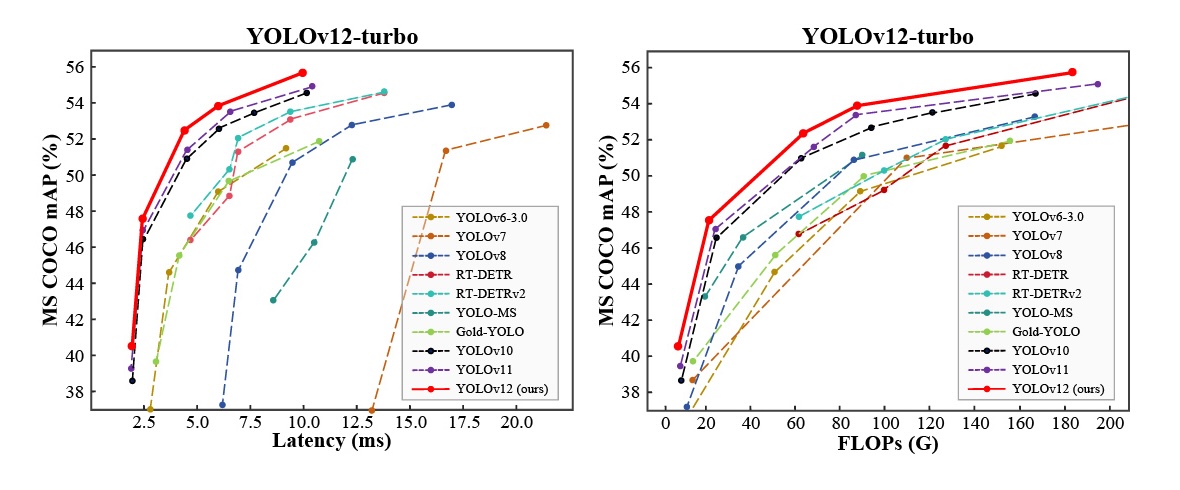
相對於 YOLOv7~YOLOv8 ,YOLOv12 的核心技術改進如下:
1. 更先進的 Backbone:採用了更深且更有效率的 CNN 結構,例如 RepNeXt、EfficientRep、或者稀疏卷積組合。引入了可學習 scale attention modules(尺度注意模組),加強對小物體與遠距離物體的辨識。
2. 改良的 Neck 結構:使用類似於 BiFPN(雙向特徵金字塔) 的結構,但加入 高階特徵整合(High-Resolution Feature Fusion)。能夠更加有效地將不同層級的資訊融合,提升對複雜場景的識別能力。
3. 動態篩選(Dynamic Label Assignment):不再僅依賴固定的 anchor 或 IoU 閾值,而是根據當下的 feature map 表現,自動分配學習權重。減少了錯誤正樣本/負樣本配對的機率,提升學習穩定性與準確度。
4. 改進的損失函數:導入 Distribution Focal Loss v2(DFL v2),進一步提升定位精度。新增 語義一致性損失(Semantic Consistency Loss),強化對遮擋或相似物體的區分能力。
以下用幾個比較表來了解一下YOLOv12的定位差異:
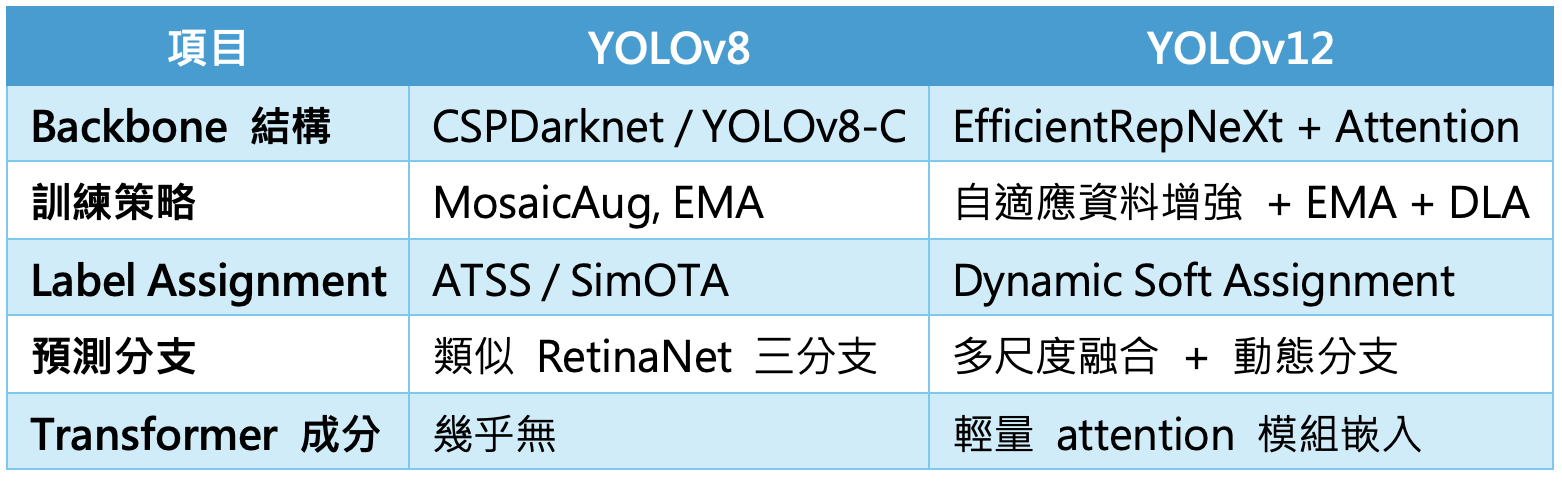
YOLOv12與YOLOv8的核心技術差異
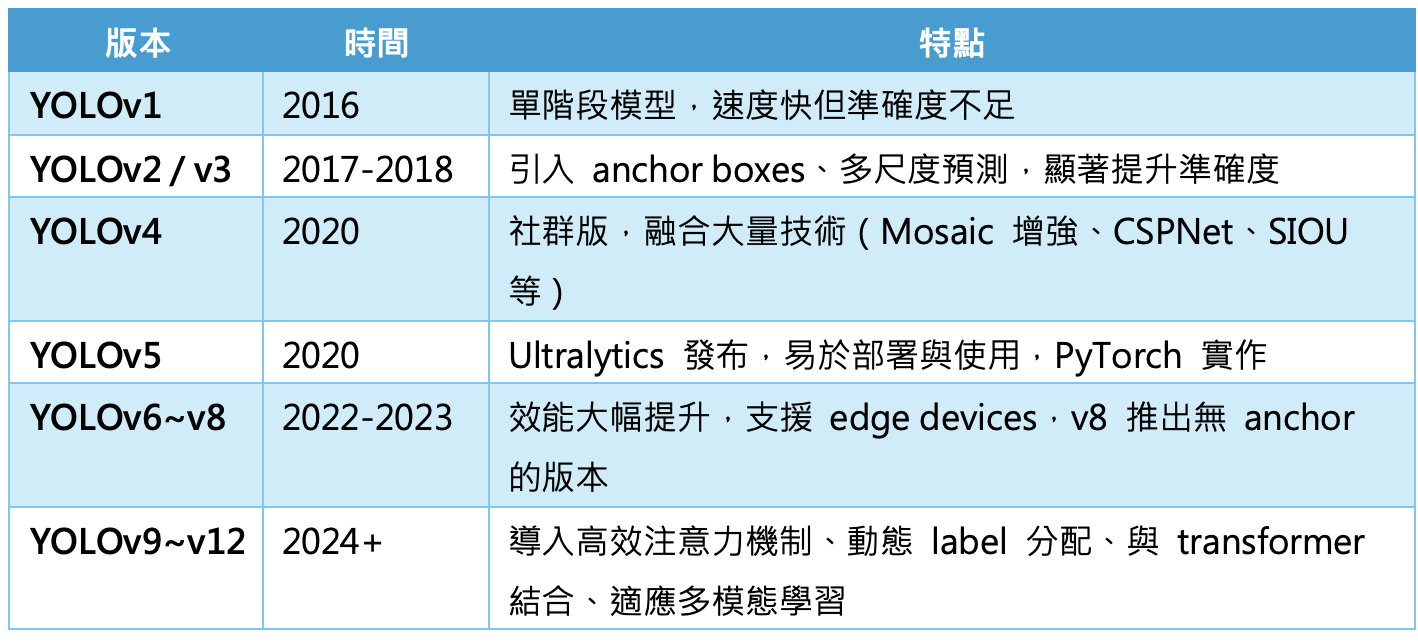
YOLO版本的演進與特點比較
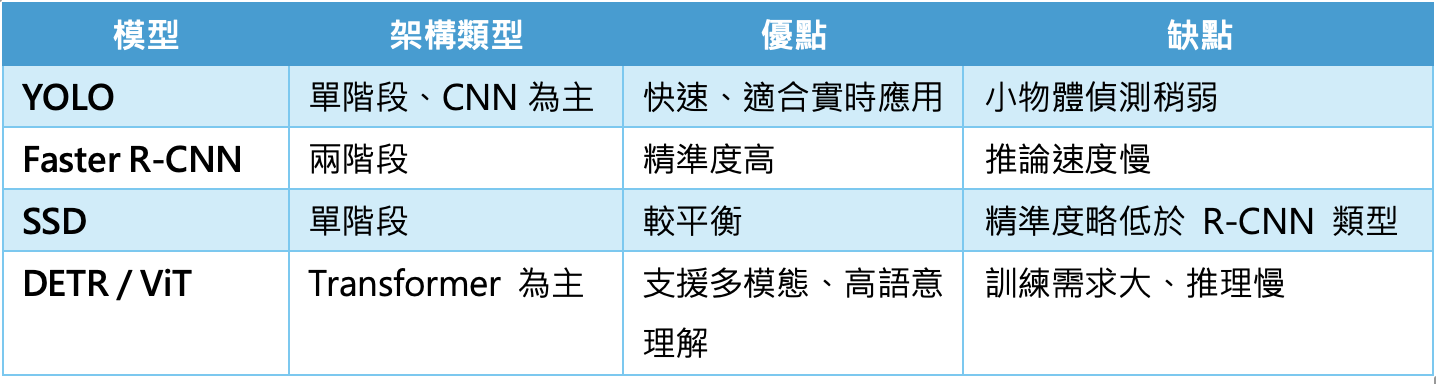
YOLO與其他視覺模型的特色比較
與ViT(Vision Transformer)相比,YOLOv12 保留了 CNN 的優勢,尤其在「小樣本」、「快速反應」、「邊緣部署」等場景中更具實用性,而 ViT 則在高語意抽象任務(如 VQA、多模態推理)中表現更佳。
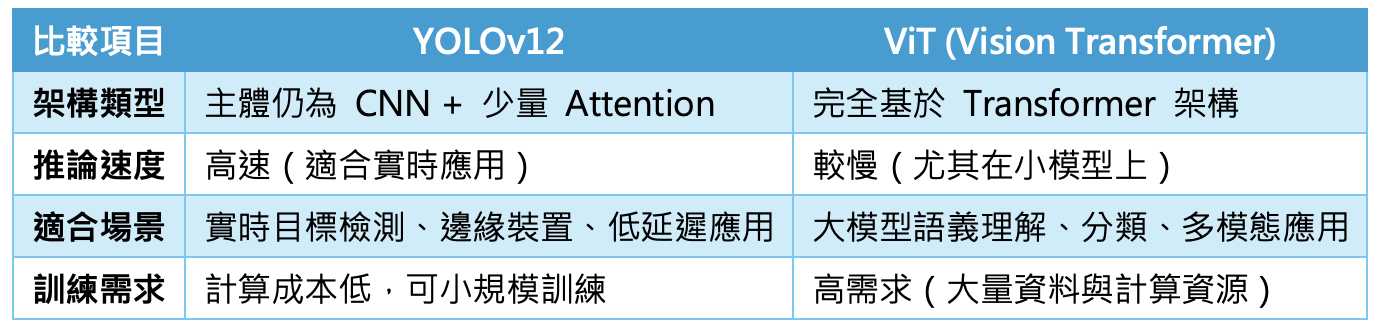
YOLOv12與ViT的比較表
小結
事實上,YOLOv12 已不再僅限於純目標偵測任務,而是逐步邁向多任務與多模態融合。例如它可作為VLM的前端模組,用於預先檢測圖像中的物件,提供 VLM 模型初始的「區域提議(region proposals)」。也能在 Grounding VLM 任務(如 Grounding DINO、OFA、GLIP)中與語言輸入結合,用於「給定文本描述 → 找出對應物件」的任務。
此外,YOLOv12 快速、準確的特徵提取能力,有助於減少 VLM 的運算負擔,提升整體推理效率。這些優勢讓 YOLOv12 成為實現智慧城市、自駕車、醫療影像與工業檢測等應用的基礎元件。YOLOv12 的開源與模組化設計也讓其極具開發者友善性,易於部署於邊緣裝置(如手機、IoT、無人機)中,使其成為連結 AI 研究與產業落地的關鍵橋樑。
(責任編輯:歐敏銓)
》延伸閱讀:

- Molex為AI資料中心關鍵任務打造創新互連解決方案 - 2025/06/05
- 【開源專案】基於 MCP+ESP32 的《小智AI聊天機器人》 - 2025/06/04
- 耐能KNEO Pi開發平台助力開啟邊緣AI硬體新時代 - 2025/06/04
訂閱MakerPRO知識充電報
與40000位開發者一同掌握科技創新的技術資訊!

