參賽團隊名稱:你是我的眼
提案動機:
現今的視障者於行走時會需要導盲犬、導盲杖,或是他人的幫助。但是導盲犬訓練不易,供不應求,而導盲杖能力也有所侷限,不能完全知道前方的狀況。而視障者因視覺障礙,所以無法透過視覺來建構空間地圖,因此若能利用語音溝通,幫助視障者建立更加完善、豐富的心理地圖,便能有助於降低視障者走出戶外的屏障。我們希望設計一個能輔助視障者行走的智慧導盲車,協助視障者在獨處或不便使用輔具的情況下也能容易行動,並且利用智慧導盲車結合其他感應器,提供多項功能,使智慧導盲車除了協助視障者避障,還能幫助視障者了解周遭環境的資訊,減少視障者多餘的負擔。
使用之軟硬體
A. 硬體
-
-
-
- ROSKY
-
-
-
-
-
-
- Lidar 光達
- 攝影機
- Neuron Pi 主控版
- CPU:Intel Atom-E3930
- RAM:8GB
- Storage:32GB
- VPU:Intel® Movidius™ Myriad™
-
-
-
B. 軟體
-
-
-
- Ubuntu 18.04
- Robot Operating System (ROS,機器人作業系統)
-
-
成果介紹
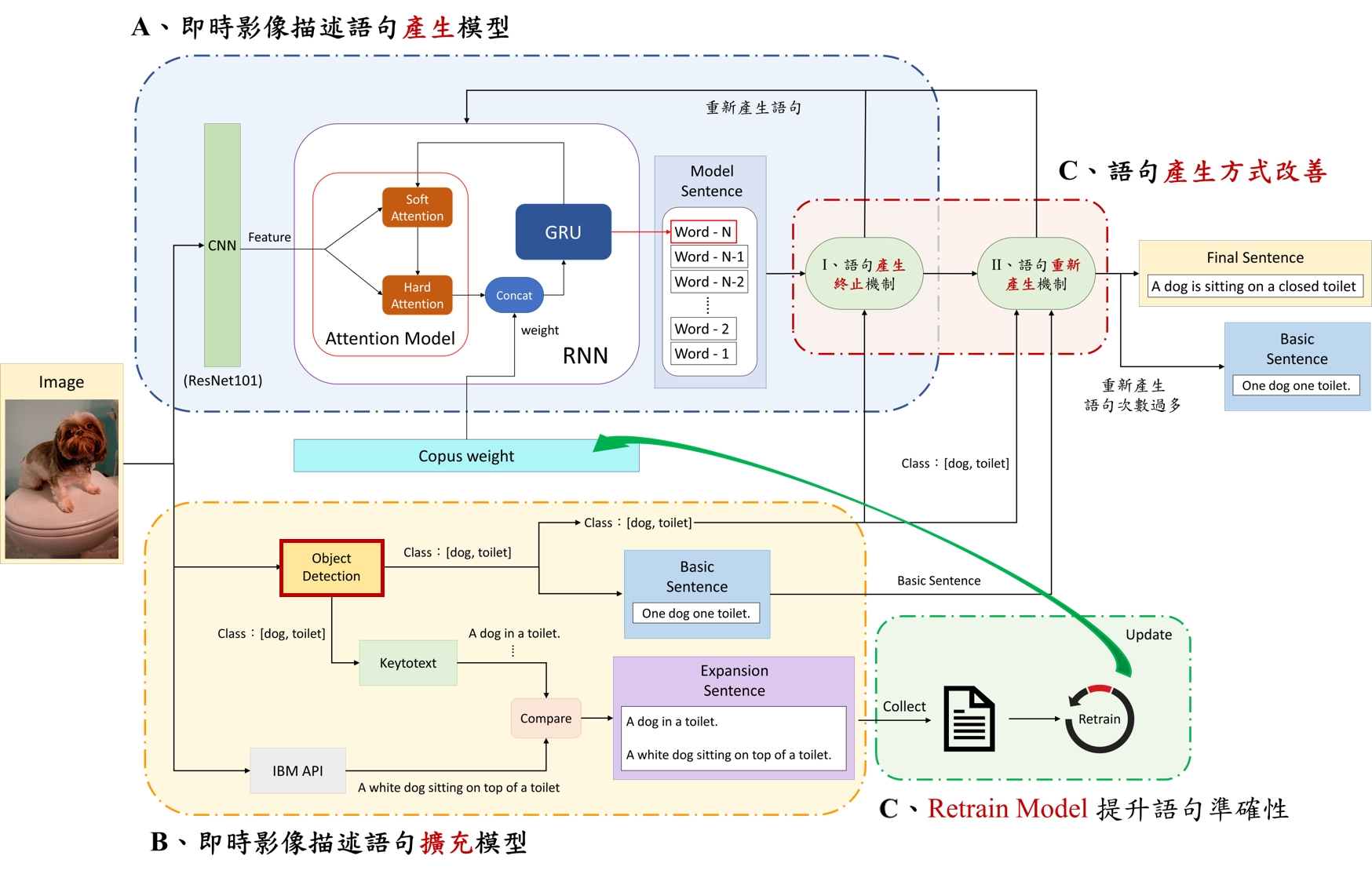
A. 語句產生模型
在訓練語句產生模型的部份,我們使用了 COCO Dataset 約 30000 張的圖像來訓練與句模型,並搭配後續的擴充模型與多項機制使我們的模型的輸出語句能更為準確。
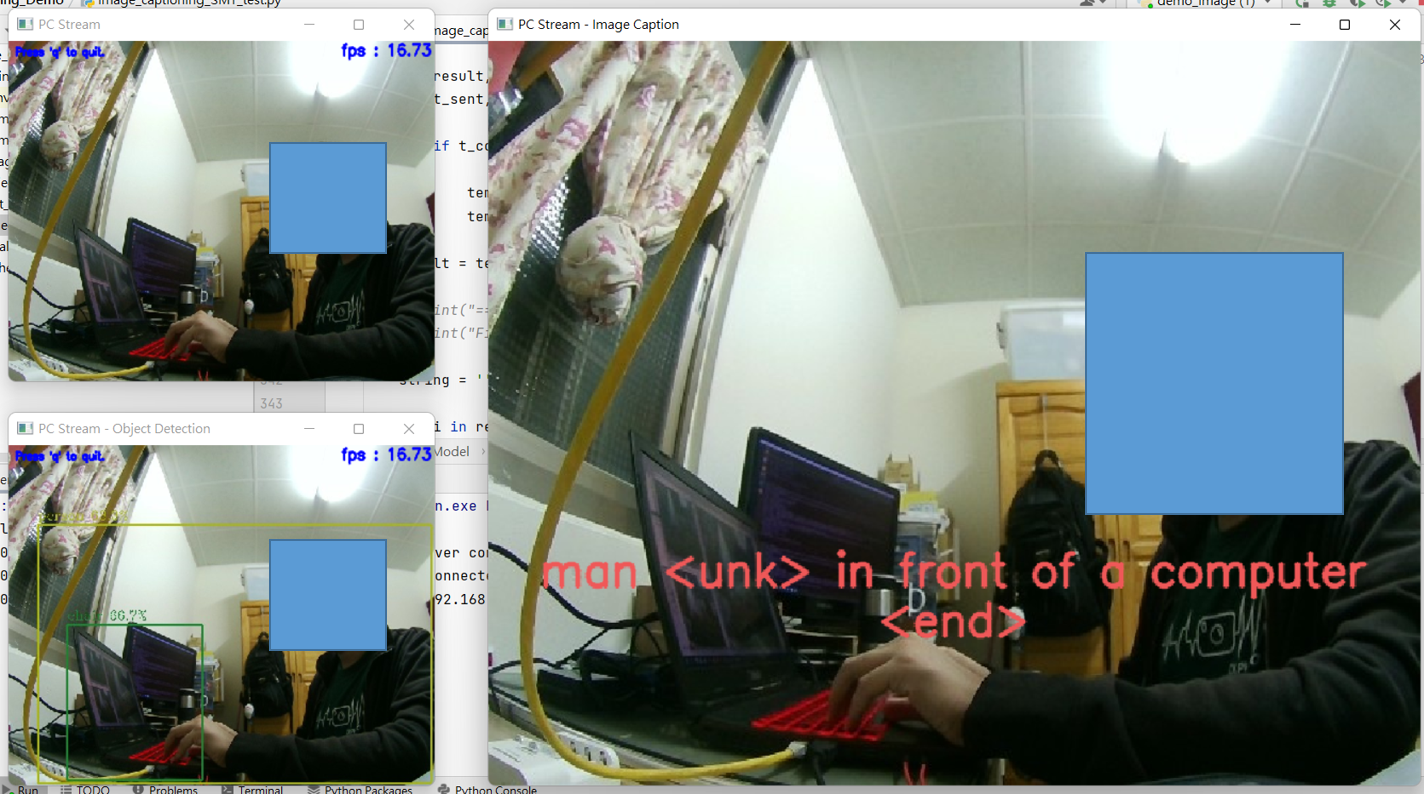
▲ 圖片左上方為目前的即時影像,左下方為經由OpenVINO加速後的物件辨識模型的辨識結果,右方則為描述語句產生模型的產生語句。
B、透過 OpenVINO 加速物件辨識模型
由於自走車的硬體效能有限,因此我們透過 OpenVINO 加速物件辨識模型 (下圖紅框處 ) 來提升模型於導盲車上執行效能。
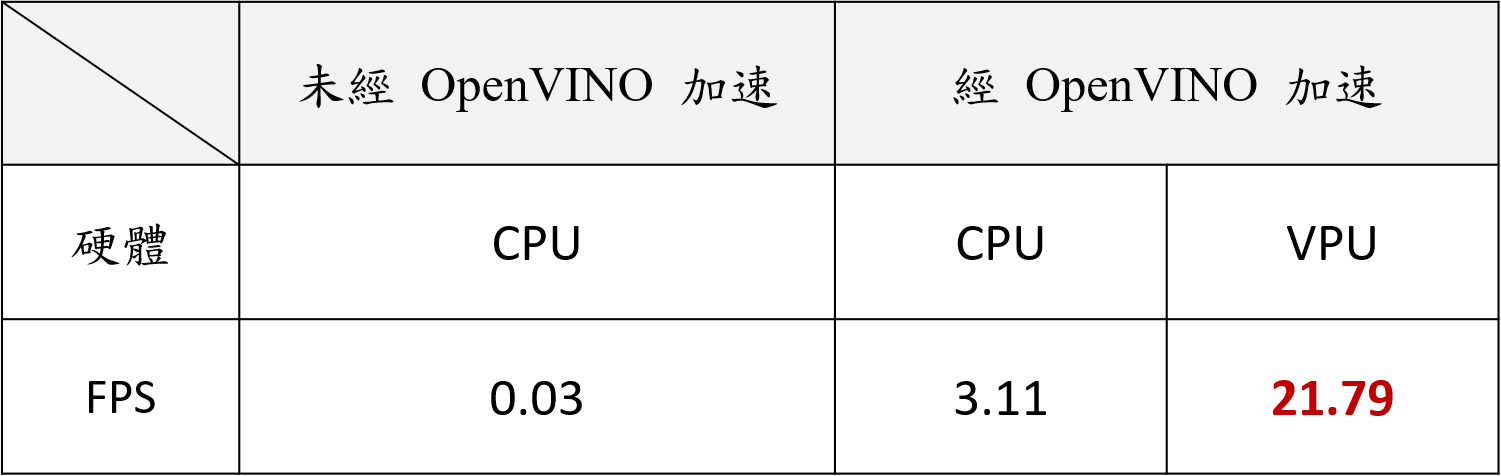
透過 Model Optimizer 轉換後的模型透過 Benchmark Tool 估計轉換後的模型 Inference 之效能約為29.73 FPS (如下圖)

在透過 Inference Engine 將轉換後的 IR Model Inference 後,執行在 Movidus VPU 上速度將比 CPU 提升 6~7 倍。

透過下圖的比較可以發現,經 OpenVINO 轉換後的模型搭配 Movidus 可大幅度的提高執行效能。